Beyond Engagement: Aligning Algorithmic Recommendations With Prosocial Goals
Beyond Engagement: Aligning Algorithmic Recommendations With Prosocial Goals

![$hero_image['alt']](https://partnershiponai.org/wp-content/uploads/2021/01/Recommender-Algorithms-Blog-Post_03_011821.png)
Much of the media we see online — whether from social media, news aggregators, or trending topics — is algorithmically selected and personalized. Content moderation addresses what should not appear on these platforms, such as misinformation and hate speech. But what should we see, out of the thousands or millions of items available? Content selection algorithms are at the core of our modern media infrastructure, so it is essential that we make principled choices about their goals.
The algorithms making these selections are known as “recommender systems.” On the Internet, they have a profound influence over what we read and watch, the companies and products we encounter, and even the job listings we see. These algorithms are also implicated in problems like addiction, depression, and polarization. In September 2020, Partnership on AI (PAI) brought together a diverse group of 40 interdisciplinary researchers, platform product managers, policy experts, journalists, and civil society representatives to discuss the present and future of recommender systems. This unique workshop on recommender-driven media covered three topics:
- How recommenders choose content today.
- What should be the goal of recommenders, if not audience engagement?
- Emerging technical methods for making recommenders support such goals.
Several promising directions for future recommender development emerged from the workshop’s presentations and subsequent discussions. These included: more understandable user controls, the development of survey-based measures to refine content selection, paying users for better data, recommending feeds not items, and creating a marketplace of feeds. The workshop also resulted in the first-ever bibliography of research articles on recommender alignment, as contributed by workshop participants.
How recommenders choose content
Recommender systems first emerged in the mid-1990s to help users filter the increasing deluge of posts on Usenet, then the main discussion forum for the fledgling Internet. One of the very first systems, GroupLens, asked users for “single keystroke ratings” and tried to predict which items each user would rate highly, based on the ratings of similar users. Netflix’s early recommender systems similarly operated on user-contributed star ratings. But it proved difficult to get users to rate each post they read or movie they watched, so recommender designers began turning to signals like whether a user clicked a headline or bought a product. By the mid-2000s, systems like Google News relied on a user’s click history to select personalized information.
Today’s recommender systems use many different kinds of user behavior to determine what to show each user, from clicks to comments to watch time. These are usually combined in a scoring formula which weights each type of interaction according to how strong a signal of value it’s thought to be. The result is a measure of “engagement,” and the algorithmic core of most recommender systems is a machine learning model that tries to predict which items will get the most engagement.
Engagement is closely aligned to both product and business goals, because a system which produces no engagement is a system which no one uses. This is true regardless of the type of content on the platform (e.g. news, movies, social media posts) and regardless of business model (e.g. ads, subscriptions, philanthropy). The problem is that not everything that is engaging is good for us — an issue that has been recognized since the days of sensationalized yellow journalism. The potential harmful effects of optimizing for engagement, from the promotion of conspiracy theories to increased political polarization to addictive behavior, have been widely discussed, and the question of whether and how different platforms are contributing to these problems is complex.
Even so, engagement dominates practical recommendations, including at public-interest news organizations like the BBC. Sometimes high engagement means the system has shown the user something important or sparked a meaningful debate, but sensational or extreme content can also be engaging. Recommender systems need more nuanced goals, and better information about what users need and want.
Building better metrics
Most modern AI systems are based on optimization, and if engagement is not a healthy objective then we need to design better processes for measuring the things we care about. The challenge that recommender designers face is expressing high-level concepts and values in terms of low-level data such as clicks and comments.
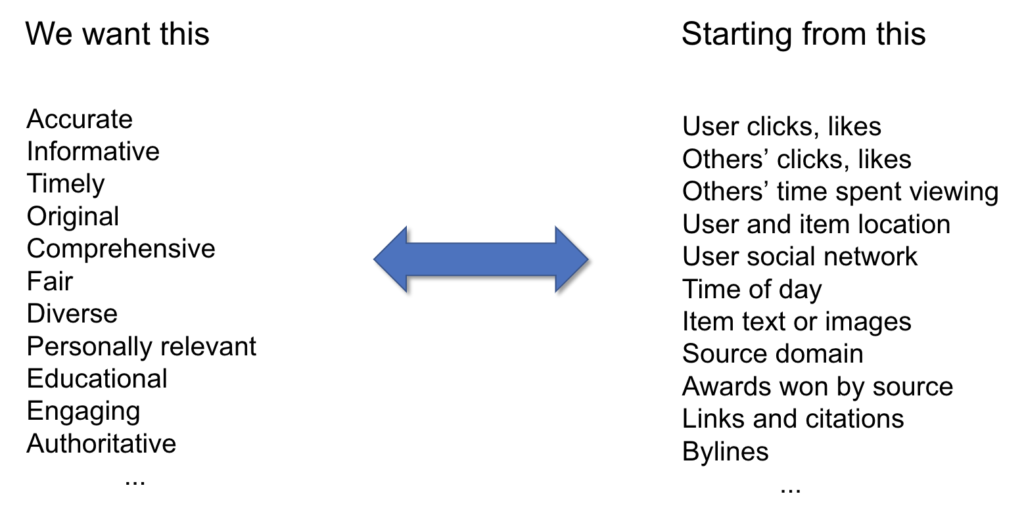
There’s a huge gap between the high-level qualities on the left side of the above graphic and the low-level data on the right, which includes user clicks and likes, the digital representation of the content itself, and metadata such as user and item location. The concepts we care about have to be operationalized — that is, translated from abstract ideas to something that can be repeatedly measured — before they can be used to drive AI systems. As a simple example, the “timeliness” of an item can be defined so that posts within the last day or the last week are considered most timely and gradually age out. Recent PAI research analyzed how Facebook operationalized the much more complex concept of a “meaningful social interaction,” and how YouTube operationalized “user satisfaction” as something more than just the time spent watching videos.
More complex ideas like “credibility” or “diversity” have proven quite difficult to translate into algorithmic terms. The News Quality Initiative (NewsQ) has been working with panels of journalists and technologists to try to define appropriate goals for content selection. As one of the journalists put it, “any confusion that existed among journalists regarding principles, standards, definitions, and ethics has only travelled downstream to platforms.”
The NewsQ panel studying opinion journalism recommended that “opinion” content should be clearly labelled and separated from “news” content, but noted that these labels are not used consistently by publishers. The NewsQ analysis of local journalism counted the number of news outlets which appeared in the top five stories from each place, e.g. “in the Des Moines feed we reviewed, 85 of 100 [top five] articles were pulled from four outlets.” The report calls for increased outlet diversity, but does not specify what an acceptable number of outlets in the top five results would be. While there is a deep history of journalistic practice and standards that can guide the design of news recommenders, defining a consensus set of values and translating them into algorithmic terms remains a challenge.
Even well-chosen metrics suffer from a number of problems. Using a metric as a goal or incentive changes its meaning, a very general problem sometimes known as Goodhart’s law. Metrics also break down when the world changes, just as a number of machine learning models stopped working when COVID reshaped the economy. And of course, qualitative research is essential: If you don’t know what is happening to your users, you can’t know that you should be measuring something new. Still, metrics are indispensable tools for grappling with scale.
As is true of AI in general, many of the problems with recommenders can be traced to mismatches between a theoretical concept and how it’s operationalized. For example, early news recommender systems operationalized “valuable to user” as “user clicked on the headline.” Clicks are indeed a signal of user interest, but what we now call “clickbait” lives entirely in the difference between user value and user clicks.
Controls and surveys
Many of the potential problems with recommenders might be alleviated by giving users more control. Yet few users actually use controls when offered: workshop participants who run recommenders noted that only one or two percent of their users actually adjust a control. It’s possible that this is because the controls that have been offered so far aren’t that well-designed or effective. For example, it’s not immediately obvious what will happen when you click on “see less often” on Twitter or “hide post” on Facebook. Better feedback on what such controls do might encourage their use, and one interesting idea is to show users a preview of how their feed will change.
Providing better control over content selection is crucial because it gives users agency, and also a kind of transparency as controls reveal something of how the underlying algorithm works. Yet even if controls were ten times as popular, most users would still not be using them. This means that a recommender’s default settings need to account for goals other than engagement, using some other source of data.
Surveys can offer much richer data than engagement because a survey question can ask almost anything. Surveys can help clarify why people use products the way they do, and how they feel about the results. Facebook asks users whether particular posts are “worth your time,” while YouTube sometimes asks users how satisfied they are with their recommendations. These are much more nuanced concepts than “engagement.” This sort of survey response data is usually used to train a machine learning model to predict people’s survey responses, just as recommenders already try to predict whether a user will click on something. Predicted survey answers are a nuanced signal that can be added into standard recommender scoring rules and directly weighted against other predicted behavior such as clicks and likes.
Despite their flexibility, there are a number of problems with using surveys to control content selection. The biggest problem is that people don’t come to platforms to fill out surveys. Too many surveys cause survey fatigue, where people become less likely to respond to surveys in the future. This severely limits the amount of data that can be collected through surveys, which makes the models constructed from survey responses far less accurate. Also, certain types of people are more or less likely to respond to surveys and this leads to survey bias. Opt-in surveys also don’t provide good data on individuals over time.
Many of these problems could be solved by paying a panel of users for more frequent feedback. It’s easy to tell if showing an article leads to a click or a share, but much harder to tell if it contributes to user well-being or healthy public discussion. To drive recommender behavior, we’ll need to know not just what users think about any particular item, but how their opinion changes over time as the algorithm adjusts to try to find a good mix of content.
Well-being metrics
AI developers are not the first people to think about the problem of capturing deep human values in metrics. Ever since GDP was introduced as a standardized measure of economic activity in 1934 it has come under criticism for being a narrow and myopic goal, and researchers have looked to replace it with more meaningful measures.
In the last decade, well-being measures have become increasingly used in policy-making. While the question “what is happiness?” is ancient, the 20th century saw the advent of positive psychology and systematic research into this question. Well-being is a multi-dimensional construct, and both subjective and objective measures are needed to get a clear picture. For example, the OECD Better Life Index includes both crime rates and surveys asking if people “feel safe walking alone at night.” To demonstrate how well-being metrics work, workshop participants took a survey which measured well-being across a variety of dimensions.
The IEEE has collected hundreds of existing well-being metrics that might be relevant to AI systems into a standard known as IEEE 7010. It also advocates a method to measure the well-being effect of a product change: take a well-being measurement before and after the change, and compare that to the difference in a control group of non-users. Facebook’s “meaningful social interaction” research is also framed in terms of well-being.
The well-being metrics used in policy-making don’t provide any sort of grand answer to the question of what an AI system like a recommender should be trying to achieve, and they’re not going to be specific enough for many AI domains. But they do have the advantage of representing a normative consensus that has developed over decades, and they provide guidance on the types of human experience worth considering when designing a metric.
Recommender recommendations
Despite widely differing perspectives, concerns, and types of recommenders, a number of themes emerged from the presentations and discussions. The practice of recommender alignment is in its infancy, but there are a number of places where progress can be made in the near future.
- Build better controls
While recommenders have offered user controls of one sort of another for many years, they still mostly aren’t used. That might change if the controls were better and not simply a button that says “I don’t want to see this item.” More expressive controls could adjust the proportions of different topics, or the degree to which internal signals like news source credibility estimates shape content ranking. It remains challenging to communicate to users what a control does and give appropriate feedback. One possibility is showing which items would be added or removed as the user adjusts a control, and there is great opportunity for experimentation.
- Develop standardized survey-based metrics
Engagement isn’t going away, but we need better measures to capture what it misses. YouTube has begun incorporating data from user satisfaction surveys into recommendations, while Facebook uses several different types of questions. Carefully designed survey measures can provide critical feedback about how a recommender system is enacting high-level values. Standardized questions would provide guidance on what matters for recommenders, how to evaluate them, and allow comparison between different systems.
- Pay users for better data
Voluntary survey responses have not produced enough data to provide accurate, personalized signals of what should be recommended. The next step is to pay users for more detailed data, such as by asking them to answer a question daily. Such data streams could provide rich enough feedback to attempt more sophisticated techniques for content selection, such as reinforcement learning methods which try to figure out what will make the user answer the survey question more positively.
- Recommend feeds, not items
Almost all production recommender systems are based on scoring individual items, then showing the user the top-ranked content. User feedback is used to train this item scoring process, but these models can’t learn how to balance a mix of different types of content in the overall feed. For example, a naive news ranker might fill all top 10 slots with articles about Trump because they get high engagement. Even if each of these stories is individually worthwhile, the feed should likely include other topics. Existing recommender algorithms and controls are almost entirely about items, instead of taking a more holistic view of the feed.
- Incentivize the creation of different feeds
Rather than trying to create one feed algorithm that fits everyone, we could have a variety of different feeds to serve different interests and values. If you trust the BBC, you might also trust a recommendation algorithm that they create, or their recommended settings for a particular platform. Similarly, you might trust a feed created by a doctor for health information. We normally think of media pluralism as being about a diversity of sources, but it may be important to have a diversity of feeds as well.
Further reading
This list of research articles was solicited from workshop attendees. It’s by no means comprehensive, but is meant to serve as an introduction to the field of recommender alignment, including the intersection of recommenders with social issues such as addiction and polarization.
What is recommender alignment?
What are you optimizing for? Aligning Recommender Systems to Human Values
Jonathan Stray, Steven Adler, and Dylan Hadfield-Mennell (2020)
Connects AI alignment to the practical engineering of recommender systems. Or see the paper video.
Science Communication Desperately Needs More Aligned Recommendation Algorithms
Lê Nguyên Hoang (2020)
If people are getting science information (e.g. COVID19) through recommenders, then those algorithms need to understand what quality science is.
Human Compatible: Artificial Intelligence and the Problem of Control
Stuart Russell (2019)
The definitive reference on AI alignment generally. Also see a five-minute video from Russell introducing the concept.
Values
Artificial Intelligence, Values, and Alignment
Iason Gabriel (2020)
A moral and political philosophy analysis arguing that “values” for AI can only come from social deliberation.
On the Democratic Role of News Recommenders
Natali Helberger (2019)
A discussion of the challenges and opportunities for algorithmic news distribution, from the view of political theory.
Recommender Systems and their Ethical Challenges
Silvia Milano, Mariarosaria Taddeo and Luciano Floridi (2019)
A systematic analysis of the ethical areas of concern regarding recommender systems
Social choice ethics in artificial intelligence
Seth Baum (2020)
How social choice theory on voting intersects with AI systems, and what problems it can’t solve.
Alignment algorithms
Inverse Reward Design
Dylan Hadfield-Menell et. al.
Introduces inverse reward design (IRD) “as the problem of inferring the true objective based on the designed reward and the training.”
From Optimizing Engagement to Measuring Value
Smitha Milli, Luca Belli, Moritz Hardt (2020)
Determines how to weight different interactions on Twitter (e.g. retweet vs. fav) as signals of user “value” through latent variable inference from observed use of the “see less often” control.
Recommending what video to watch next: A Multitask Ranking System
Zhao et al.
A description of of YouTube’s deep learning-based ranking framework, and how it balances “engagement objectives” with “user satisfaction objectives.”
Design and Controls
Beyond Optimizing for Clicks: Incorporating Editorial Values in News Recommendation
Lu, A. Dumitrache, D. Graus (2020)
A news organization successfully used their recsys to increase the diversity of audience reading.
Designing for the better by taking users into account: A qualitative evaluation of user control mechanisms in (News) recommender systems
Harambam et al. (2019)
A user study that tested sliders to control topics, algorithms, etc. on a recsys mockup.
The Illusion of Control: Placebo Effects of Control Settings
Vaccaro et al. (2018)
Users appreciate recommender controls, even if they don’t work. Either way, people find creative workarounds to get what they want.
Recommender Audits
Auditing News Curation Systems: A Case Study Examining Algorithmic and Editorial Logic in Apple News
Jack Bandy, Nicholas Diakopoulos (2019)
An analysis of Apple News content in the human-curated vs. algorithmically curated sections
Algorithmic extremism: Examining YouTube’s rabbit hole of radicalization
Mark Ledwich, Anna Zaitsev (2020)
Analysis of recommender traffic flows between different categories of more and less extreme content.
Evaluating the scale, growth, and origins of right-wing echo chambers on YouTube
Hosseinmardi et al. (2020)
Consumption of far-right content on YouTube is consistent with broader patterns across the web, which complicates the causal role of recommender systems.
Participatory Design and Multi-stakeholder Recommenders
WeBuildAI: Participatory Framework for Algorithmic Governance
Lee et al. (2019)
Researchers worked with multiple stakeholders in a donated food delivery non-profit, developing a quantitative ranking model from their input. Also a talk.
What If I Don’t Like Any Of The Choices? The Limits of Preference Elicitation for Participatory Algorithm Design
Samantha Robertson and Niloufar Salehi (2020)
Existing societal inequalities can constrain users’ ability to exploit algorithmically provided choices, for example due to a lack of information or the cost burden of choosing the “best” option.
Multistakeholder recommendation: Survey and research directions
Abdollahpouri et. al. (2020)
A review of the field of multi-stakeholder recommendation algorithms, which attempt to simultaneously account for the needs of users, creators, platforms and the public.
Filter bubbles, polarization and conflict
Polarization and the Global Crisis of Democracy: Common Patterns, Dynamics, and Pernicious Consequences for Democratic Polities
Jennifer McCoy, Tahmina Rahman, and Murat Somer (2018)
One of the best reviews of why polarization is something we should care about: it can be a cause (not just a correlate) of democratic erosion.
Social Media, News Consumption, and Polarization: Evidence from a Field Experiment
Roee Levy (2020)
Getting people to follow counter-ideological news sources on Facebook for a month slightly reduced polarization.
Cross-Country Trends in Affective Polarization
Boxell, et al. (2020)
Measures polarization trends across nine OECD countries. Tends to disfavor the emergence of the internet and rising economic inequality as explanations.
Is the Internet Causing Political Polarization? Evidence from Demographics
Boxell, et al. (2017)
In the US, growth in polarization in recent years is largest for the demographic groups least likely to use the internet and social media.
It’s not the technology, stupid: How the ‘Echo Chamber’ and ‘Filter Bubble’ metaphors have failed us
Axel Bruns (2019)
Reviews empirical investigations of filter bubbles etc. and argues that the concept is under-specified and the evidence for their existence is poor.
Fairness
FaactRec 2020 workshop
The most recent papers at the intersection of fairness and recommenders.
Towards a fair marketplace: Counterfactual evaluation of the trade-off between relevance, fairness & satisfaction in recommendation systems
Mehrotra et al. (2018)
An analysis of artist exposure dynamics in Spotify’s music recommendations, and experiments with a popularity-based diversity metric.
Fairness in recommendation ranking through pairwise comparisons
Beutel et al. (2019)
A definition of recommender fairness in terms of pairwise rankings of items in different subgroups, and experiments in a production Google recommender.
Well-being
The Welfare Effects of Social Media
Allcott et al. (2020)
Paying people to deactivate Facebook for four weeks caused slight increases in well-being measures and slight decreases in polarization measures.
Social networking sites and addiction: Ten lessons learned
Daria Kuss, Mark Griffiths (2017)
A review of the definition of “social networking addiction,” and the evidence for its existence, including demographic and contextual variations.
A systematic review: the influence of social media on depression, anxiety and psychological distress in adolescents
Betul Keles, Niall McCrae and Annmarie Grealish (2020)
Social media use is correlated with depression and anxiety. However, there are considerable caveats on causal inference due to methodological limitations.
Policy
Why Am I Seeing This? How Video and E-Commerce Platforms Use Recommendation Systems to Shape User Experiences
Spandana Singh (2020)
A detailed report of how platforms use recommender systems and the public policy implications.
Regulating Recommending: Motivations, Considerations, and Principles
Jennifer Cobbe, Jatinder Singh (2019)
One of the most nuanced analyses of possible regulatory frameworks, focussing on “harmful” content and liability laws.
Metrics
Aligning AI Optimization to Community Well-being
Jonathan Stray (2020)
An analysis of recent Facebook and YouTube recommender changes, and how recommenders can be oriented toward well-being metrics.
What Are Meaningful Social Interactions in Today’s Media Landscape? A Cross-Cultural Survey
Litt et al. (2020)
Survey analysis, by Facebook researchers, of what makes a social interaction (online or off) “meaningful,” finding similarities across the U.S., India, and Japan.
Simple objectives work better
Delgado et al. (2019)
Case study of multi-objective optimization in a corporate setting: metrics used at Groupon to integrate expected transaction profit, likelihood of purchase, etc.